个人信息法律保护体系的建构:以信息界定与分类为前提
李立丰
(吉林大学 法学院,吉林 长春 130012)
王俊松
(吉林大学 法学院,吉林 长春 130012)
内容摘要:个人信息保护法律规范体系的建构以对信息的界定与分类为前提。通过对信息界定方式的梳理得出传统“可识别性”界定标准出现缺陷,需要以“情境说”理论进行优化的结论。在此基础上,形成以信息的敏感性为核心的“敏感信息与一般信息”二元分类模式。信息界定标准与分类前提确立后,才得以建构个人信息法律保护的体系。在法律保护体系内部,尤其注重对敏感信息的保护,通过对信息敏感层级的划分,形成民、行、刑三方为主导的多元保护模式。
关键词:信息界定;信息分类;敏感个人信息;法律保护体系
中图分类号:D924
文献标识码:A
文章编号:2095-3275(2023)02-0001-12
一、问题的提出
个人信息在数据时代强调对其价值性以及隐私性的重点保护。在信息利益价值的诱惑面前,侵犯公民个人信息的行为十分普遍,由此促使信息在数据时代成为重点关注的对象。数据时代下,公民个人信息在一定程度上会被公开,但也应当注意,信息完全被公开无异于信息主体在数据时代“裸奔”。数据时代强调维持信息价值的挖掘与保护之间的动态平衡。因此,一方面我们要正视数据时代的到来,尊重数据时代信息利用的诉求;另一方面,信息也应当在数据时代找到属于自己的堡垒,维持好信息利用与保护之间的动态平衡。
数据时代下,我国在个人信息保护的有关立法上似乎并未及时做出反应。有关个人信息保护的规定虽然体现在了诸多部门法、各法规中,但是各规范之间规定得比较混乱、缺少联动,个人信息规范保护体系尚不成熟。从我国的立法规定来看,《
中华人民共和国民法典》(以下简称
《民法典》)在第四编第六章中对个人信息的保护做出了规定,《
中华人民共和国个人信息保护法》(以下简称
《个人信息保护法》)以及《
中华人民共和国数据安全法》(以下简称
《数据安全法》)的出台更是体现了对个人信息保护的关注,《
中华人民共和国刑法》(以下简称《
刑法》)第
二百五十三条之一也对侵犯公民个人信息的行为做出了立法上的规定。由此看来,个人信息的法律保护似乎已经初具体系。然而,这些法律规定之间实则缺少了互动,甚至在外部逻辑上并不自洽。如何理解
《民法典》与
《个人信息保护法》的关系定位,是当下需要厘清的问题之一
[1]。
《民法典》中私密信息与
《个人信息保护法》中敏感信息的关系如何,并未做出说明,这两部法律都主张个人信息的界定方式以“可识别性”为标准。当具体到刑法规范中,“可识别性”识别出来的信息能否成为
刑法保护的对象,存在疑问。“可识别性”标准在数据时代下是否还具备合理性,也有待考究。如何平衡信息利用与信息保护之间的利益,成为数据时代下的重要问题。
《数据安全法》与个人信息保护之间似乎还有一段距离,其关注点在于数据安全,至于数据与个人信息的关系尚未厘清。
基于此,本文将试图厘清当下个人信息规范保护的现状,找寻个人信息规范保护混乱的原因,并以此为基础建构个人信息法律保护的体系。个人信息法律保护体系的建构始于对信息界定标准和分类模式的重构,这是关键前提和基础,其目的是为了实现
《民法典》《个人信息保护法》和《
刑法》之间关于个人信息保护规定的形式逻辑上的自洽。前提工作准备完成后,才能够进入个人信息规范保护体系建构的探讨中。
二、以情境说为指导的信息界定标准的优化
个人信息保护体系的建构始于对信息界定标准的确立。该部分首先对个人信息界定标准的现状进行梳理,在此基础上针对“可识别性”标准的缺陷以“情境说”理论对其进行优化,进而形成新的信息界定标准。
(一)信息界定标准的现状梳理
我国法律法规对个人信息(隐私)保护做出了相关规定,其中,除了
《个人信息保护法》是专门性立法规定外,其余散见于不同法律法规的部分章节中(见表1)。
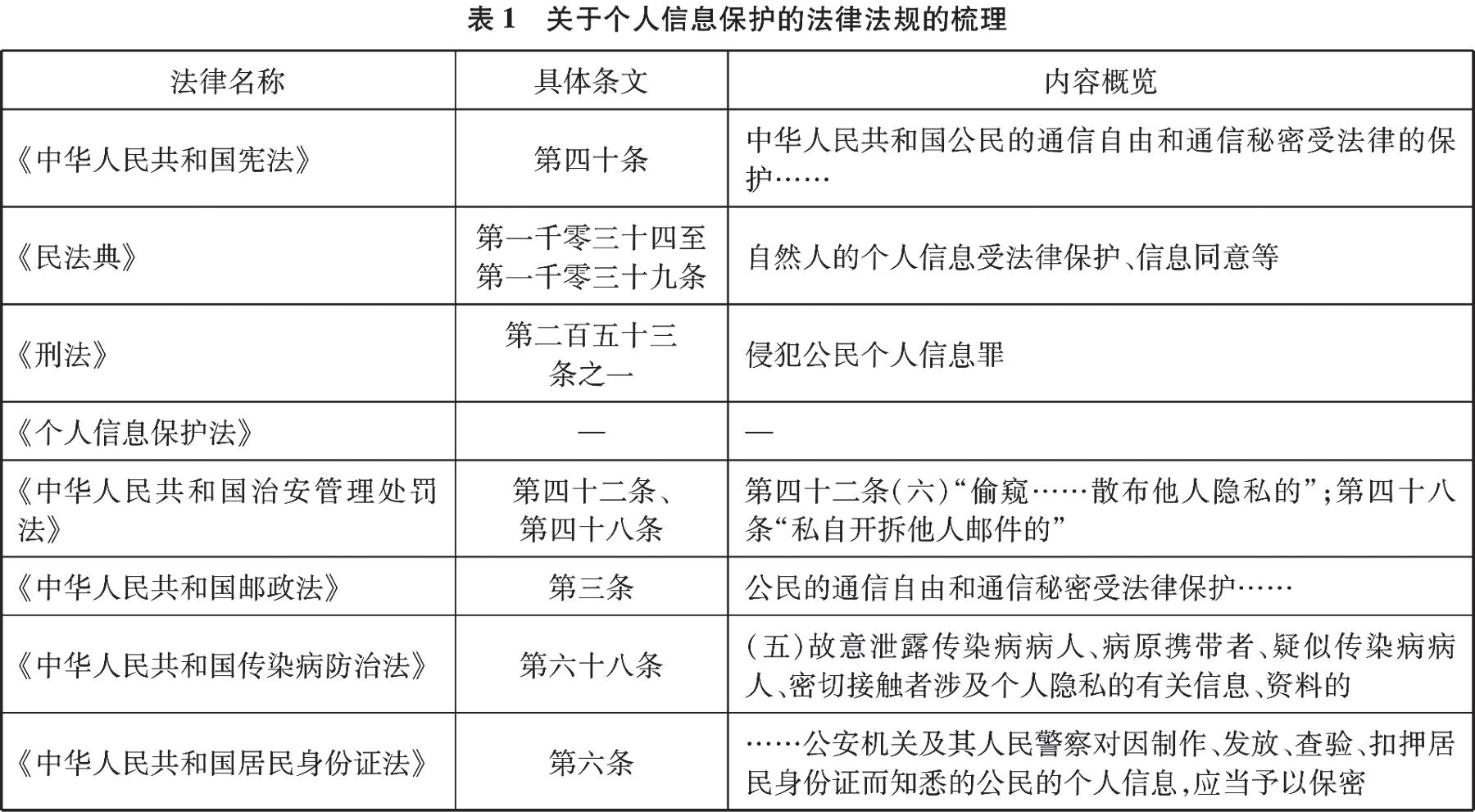
从表1中可以看出,尽管我国对个人信息的立法保护做出了丰富的规定,但是,从目前的诸多规定来看,大多数规定并未明确个人信息的界定标准。当下法律规定针对个人信息的界定标准只是稍有提及,部分采取的是默认的同类解释的方法,即现有规范对于个人信息的界定并未形成统一的意见。除上述统计外,《
最高人民法院、最高人民检察院关于办理侵犯公民个人信息刑事案件适用法律若干问题的解释》指出个人信息包括“姓名……住址等”,亦未形成确定的个人信息界定标准。
《个人信息保护法》虽然提出了个人信息的界定标准,但囿于其自身的缺陷,并不能成为普适性的标准(下节详述)。综上来看,法律保护体系建构的首要任务应是对个人信息界定标准的明确。
(二)信息界定模式的理论优化
个人信息界定标准的优化起因于“可识别性”标准自身的缺陷。信息界定标准影响信息分类模式的建构,信息分类的前提在于对各种信息的准确界定。只有明确了何种信息属于个人信息,才可以进入到个人信息内部对其进行分类。比如,将性生活记录划分为高度敏感信息的前提在于明确高度敏感信息的界定标准。信息的界定与分类之间呈现出由外到内的逻辑关系,即信息的界定属于信息外部的工作,而信息的分类仅涉及个人信息内部的工作。从这一点来看,信息分类较信息界定更为细致,毕竟信息的界定只是完成了初筛的工作,但是这一过程却发挥着前提性的关键作用。因此,需要对这一标准进行理论上的优化。
1.“可识别性”标准的缺陷。“可识别性”已经成为国内外界定个人信息的主流标准。“可识别性”标准最初依托于隐私权的有关规定。美国在《记录、计算机与公民权利》中将“可识别性”明确为个人隐私信息的界定方式,德国早在1977年也将身份“可识别性”标准在立法层面予以确立
[2]。欧盟所采取的标准也是如此,即在《个人数据保护法》以及《通用数据保护条例》中以“可识别性”作为认定自然人有关个人信息的方法。《理事会关于保护隐私和个人数据跨境流动准则的建议(2013年)》也以“可识别性”标准认定个人信息
[1]。由此可见,“可识别性”标准在数据时代日益体现出它的价值。不过,数据时代下“可识别性”并非唯一标准,比如,美国《消费者隐私权利法案(草案)》以信息的“关联性”为特征,将“连结性”作为识别个人信息的方法
[3],美国《加州消费者隐私法(2018年)》也明确指出以“关联性”为定义个人信息的标准
[2],然而,“连结性”或者“关联性”的出现并未对“可识别性”标准造成冲击,即“可识别性”标准仍然是数据时代信息界定的主流旋律
[4]。
我国法律规定也主张以“可识别性”标准来认定个人信息,而且在个人信息定义方式上采取的是“定义 不完全列举”模式。比如,
《民法典》第
一千零三十四条、
《个人信息保护法》第
四条及《
刑法》第
二百五十三条之一有关的司法解释。此外,《
电信和互联网用户个人信息保护规定》《全国人民代表大会常务委员会关于加强网络信息保护的决定》中也都赞成“可识别性”标准。事实上,
《个人信息保护法》在部分规定上学习了欧盟《一般数据保护条例》中的规定
[5],比如,其对“可识别性”界定标准的借鉴。“可识别性”标准的应用不仅局限在对个人一般信息的界定中,在其他信息界定的场合也有所应用。有学者以生物信息为例,从原则上对生物信息的识别提出了指导要求,以此影响对信息内涵与外延的界定,并实现提高生物识别信息准确性的最终目的
[6]。
尽管“可识别性”标准具备一定的优越性且被广泛应用,但是,这一标准自身存在诸多问题。该标准主要是指信息的“识别”与“被识别”,对于“可识别性”的具体定义并未统一(尤其是在隐私信息法中)
[7]。在数据时代,“可识别性”标准虽然能够轻易地从海量信息中识别到具体的个人信息,但是,其更倾向于事实与技术层面上的应用。除此之外,该标准之所以能够发展为各国通行的标准,还与其背后隐含的关于隐私权利的保护密不可分。个人信息背后以隐私权为依托,这决定了无论公法还是私法都要保护信息主体的隐私权,维护信息主体的尊严
[8]。但是,在本文看来该标准在当下出现了以下问题。
第一,“可识别性”仅能作为技术层面的标准,当上升到规范层面时会给个人信息的法律保护带来压力。这一标准属于单纯的事实或者技术上的判断,任何信息经过技术分析都能够识别到具体个人。而且,根据“可识别性”标准识别出的个人信息,从规范层面上来看一定是海量的个人信息,若这些信息都纳入法规范保护的范畴,一方面会为个人信息的法律保护工作带来巨大压力,另一方面还会无限压缩信息的利用价值。诸如个人姓名等这种能够直接被识别的信息,若不结合其他条件很难说其具备规范保护的必要性。
第二,“可识别性”标准自身的缺陷导致需要对其进行优化。“可识别性”标准容易导致个人信息的内涵和外延并不明确
[9]。对于个人信息的界定过于宽泛会造成法律保护范围过于延展,且不具有操作可行性,加重司法工作量。反之,界定过于狭窄则不利于个人信息的保护,尤其是考虑到数据时代下个人信息的发展
[10]。也就是说,“可识别性”标准并不能直接套用到
刑法领域,其只是发动
刑法的必要非充分条件
[11]。
第三,“可识别性”标准在数据时代反而不利于对个人信息的法律保护。这是因为,数据时代的特征与信息的可识别性高度关联且往来密切,信息圈因受“可识别性”标准辐射的影响正在无限制扩大,这一扩大的怪象也在逐渐吞噬着个人信息的边界
[12]。数据时代下几乎任何信息都带有一定的识别性,这些信息也存在识别度强弱上的差异。若法律对这种低识别度的信息提供保护,则会导致部分在社会上难免会被公开的信息所带来的便利与法律保护之间产生冲突。随着去识别化技术的兴起,“可识别性”标准出现了漏洞。尤其是对掌握海量信息资源和拥有强大信息处理技术的大企业来说,信息去识别化的技术处理以及“隐私增强技术”“隐私偏好平台”标准并不能很好地解决个人信息的保护问题,其需要多方面协作才会有好的效果
[13]。因此,“可识别性”标准若要进入规范层面,需要对其进行优化和修正。
2.“情境说”标准的提出。法律规范层面主张对个人信息的保护即是强调在法律规范的情境中识别个人信息。技术层面的“可识别性”若要进入规范层面,还需要对信息所处的环境进行考察,即在个人信息“可识别性”基础上引入情境说的相关理论。故本文主张在法规范层面上建立“识别 情境”二元的个人信息界定方法。信息之所以能够在规范层面发挥价值,正是因为其处于规范的语境下。实际上,情境说的有关理论也早已被重视,比如,美国在《2018年加州消费者隐私法案》开头部分明确指出情境说(various contexts)的重要性
[3]。欧洲现代隐私信息法之父也认为对信息的处理离不开其所在的背景和环境,情境说在经济合作与发展组织以及美国官方制定的相关文件中也发挥了重要作用
[14]。在我国学界中也出现了以场景抽离与场景融入相结合的方式界定敏感信息的主张
[15]。也有学者主张,信息是否值得被保护应当置于具体环境中去评价,这当然也包括对数据(信息)自身流动环境的考察
[4]。总的来说,其就是以场景(情境)为导向展开的。
因此,本文主张在“可识别性”标准基础之上,以情境说的有关理论优化对个人信息的界定标准,即法律规范层面建立“识别 情境”的个人信息认定模式。主要理由有以下两点。其一,该模式能够弥补“可识别性”标准在规范层面的不足。可识别性的定义是比较抽象的,对可识别性的理解应当借助其所处的“环境”(Context)来判断
[16]。个人信息经过“可识别性”标准识别后,若要成为规范层面的个人信息法益,还应当考虑识别后的信息在具体情景下给信息主体带来的规范意义上的风险。此外,该模式还能对“去识别化”的个人信息提供法律保护,去识别化的信息若是在具体情境中为信息主体带来风险,则仍可以对其进行规范保护。其二,该模式能够减轻司法实践中个人信息保护的工作量。“可识别性”标准导致司法实践盲目将一些公开频率较高的信息认定为保护对象,而这些信息实则缺少规范保护的必要性。这也正是情境说的优势之处,即其可以限制个人信息在法律层面的恣意认定,严格把控对个人信息的规范保护,更有利于发挥信息的利用价值。
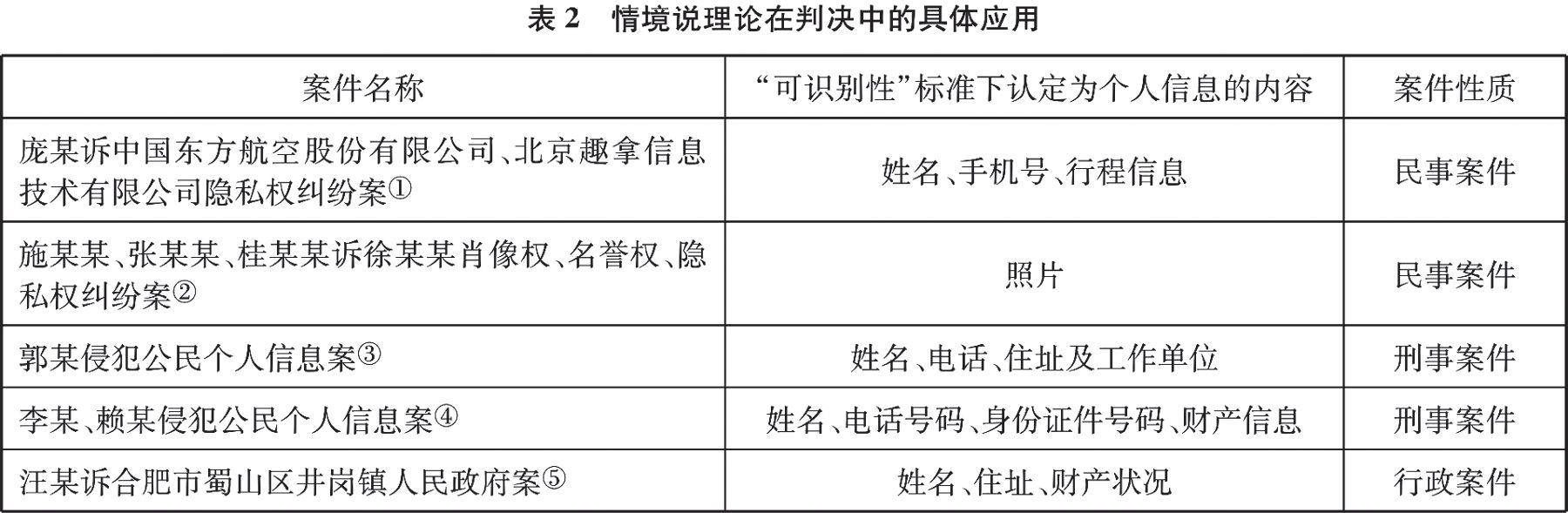
实际上,司法实践对这种二元认定模式常有应用,具体如表2所示。在表2所选取的典型案例中,之所以对诸如姓名等这种轻易被识别的个人信息进行保护,正是考虑到该种类型的信息在特定的环境中具备了法律规范保护的必要性。若不结合信息所处的具体情境,难以说明这种轻易可被识别的信息(如个人姓名)具备法律保护的必要性,否则会导致姓名等信息失去意义。
 [5][6][7][8][9]
[5][6][7][8][9]
综上所述,个人信息的界定一方面要注重对信息的识别,另一方面还要考虑到信息所处的具体环境,以此才能为个人信息提供法律保护。
三、以敏感性为核心的信息分类模式的建立
在确立个人信息界定标准的基础上,有必要围绕个人信息的分类标准进行探讨。个人信息规范保护体系建构的前提还在于明确信息的分类。信息的分类构成了对不同信息多元式保护的重要前提
[17]。因此,该部分旨在通过对当下信息分类现状的梳理,确定个人信息的二元分类模式。
(一)信息二元分类模式的形成
实践中针对个人信息的分类模式并未形成统一标准,部门法之间对个人信息的分类甚至存在抵牾。
《民法典》中采取“私密信息”与“其他信息”的分类方法,而
《个人信息保护法》采用“敏感信息与一般信息”的分类,《
最高人民法院关于审理利用信息网络侵害人身权益民事纠纷案件适用法律若干问题的规定》(以下简称《网络侵权民事纠纷规定》)采用的是“个人隐私信息与其他个人信息”的分类,《
最高人民法院关于人民法院在互联网公布裁判文书的规定》主张“隐私信息与一般信息”的分类,《
刑法》第
二百五十三条之一以及《
最高人民法院、最高人民检察院关于办理侵犯公民个人信息刑事案件适用法律若干问题的解释》中甚至未对个人信息的分类做出规定。这就造成了部门法之间在保护公民个人信息的规定上忽视了法秩序整体上的逻辑自洽性,偏离了目前对个人信息“综合治理”模式的共识
[18]。即便是在采取了相同分类方法的法律规定中,对同一概念的定义也存在差异,比如《网络侵权民事纠纷规定》与《
最高人民法院关于人民法院在互联网公布裁判文书的规定》中对隐私的规定就存在差异,这一差异在不同分类方法的规定中也有体现,如《信息安全技术个人信息安全规范》与《信息安全技术公共及商用服务信息系统个人信息保护指南》中针对敏感信息的分类
[19]。
上述现象更是强调了对信息分类的重要性。法律规范对个人信息进行体系化保护的前提是确定统一的分类标准,构建合理的信息分类模式。对个人信息类型化区分有助于法律制度与信息流动的契合,避免信息利用的利益失衡
[20]。更为关键的是,对个人信息的分类还会影响到
刑法中“情节严重”的判断,最终影响到对敏感个人信息的保护
[21]。法律规范之所以强调对个人信息进行分类保护,正是在于强调对信息保护与信息价值利用之间的利益衡量。
常见的个人信息分类方式有以下几种:人身信息与财产信息、直接识别信息与间接识别信息、隐私信息与一般信息、公开信息与非公开信息
[22],以及敏感隐私信息与一般信息。这些划分标准都是相对的。本文主张保持相对性划分的基本方法,采敏感信息与一般信息的二分法建构个人信息的保护框架体系。理由包含以下两点。
其一,实践中对个人信息的分类存在缺陷。诸如人身与财产信息、直接与间接识别信息、隐私与一般信息以及公开与非公开信息的分类模式,都无法适应数据时代信息利用与保护的趋势。这些分类模式或过于片面,如人身与财产信息的分类方法;或过于狭隘,以至于无法囊括数据时代的所有信息,如公开与非公开信息的分类方法;或无法将信息分类模式上升到规范层面,如直接与间接信息的分类方法;或和敏感与一般信息的分类模式属于同义转换,如隐私与一般信息的分类方法。
其二,“敏感信息与一般信息”分类模式的优越性在当下已被关注。比如,
《个人信息保护法》《信息安全技术个人信息安全规范》以及《信息安全技术公共及商用服务信息系统个人信息保护指南》均采这一分类方法。从多方面考察,敏感信息与一般信息的区分模式都能够为个人信息的区别化保护奠定基础
[24]。敏感信息与非敏感信息的划分方法在数据时代下存在重要意义
[25]。法律法规对于敏感信息的强保护和一般信息(非敏感信息)的弱保护是在衡量信息的利用价值与保护价值之后做出的选择。综上来看,敏感信息与一般信息的分类方法更能够适应我国针对个人信息法律保护的诉求。
(二)信息二元分类模式的适用
在确立信息界定标准的基础上,厘清不同信息类型的内涵是促进二元分类模式适用不可回避的问题。
在本文看来,个人敏感信息包含以下三种。(1)经过“可识别性”标准识别出的直接关联个人的信息。此类信息如就医记录、性生活记录以及银行卡密码等。这种信息的特点是公共性低、私密性高,信息主体对其的敏感性、保护欲极高,其一旦被泄露将会造成信息主体的恐惧与不安。(2)经过“可识别性”标准识别出来,而后在具体情境中为个人带来危险的信息。此类信息如手机号码、行动轨迹等。有学者直接将敏感信息列举为诸如手机号码、种族以及宗教信仰等,从而应当给予严格保护
[26]。但是,像手机号码这种信息若法律规范给予保护,这一保护成本未免过大。其实,将此类信息暂定为“摇摆信息”更具有一定的合理性,即是否保护该类信息应当考虑其所处的具体情境。(3)其他经去识别化后的信息若在具体情境中给信息主体带来了危险,依然具备规范保护的必要性。相比之下,一般信息指的是单纯的经可识别技术识别出来的信息,比如上网浏览记录、网页搜索内容、出行活动轨迹以及工作专业等。此类信息的识别仅仅涉及技术、事实上的操作,信息主体一般对该类信息敏感程度较低,并允许其在一定程度上被公开。
此外,受二元分类模式的影响,还需对
《个人信息保护法》中的敏感信息与
《民法典》中的私密信息的关系做出梳理。对此,有学者主张两者存在交叉关系
[27]。在本文看来两者属于包含关系,即
《个人信息保护法》